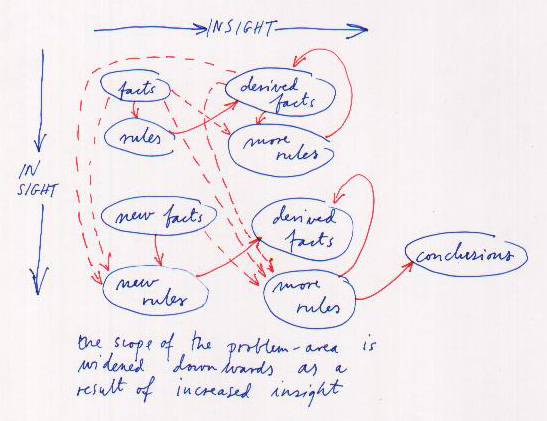
|
||||||||
|
How is a problem-area model built with Pro/3? |
||||||||
|
||||||||
|
Step 1 - Defining the Sentence Model |
||||||||
|
Entering sentences cannot be carried out without prior preparation. This preparation is called sentence modeling, and involves defining the types of predicates, subjects and objects from which sentences can be built. Pro/3 can handle two main classes of sentences, that is, subject-predicate sentences and subject-predicate-object sentences. This imposes some limitations with respect to the sophistication of the natural language capabilities of Pro/3, however this is not very important for the overall purpose of problem solving. Subjects and objects are actually the same type of objects - called entity types in Pro/3. An entity type has (besides a name) a fixed (and ordered) set of data element types. Predicate types may or may not have data element types. Predicates used in subject-predicate sentences are called unary, while predicates in subject-predicate-object sentences are called binary. |
||||||||
|
||||||||
|
Step 2 - Entering Sentences |
||||||||
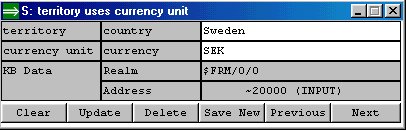
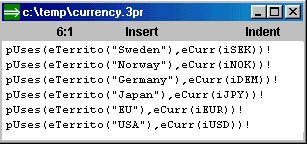
| After the first-cut version of the sentence model has been defined, then the knowledge base (KB) is ready for entering of facts. There are several choices with regards to the practical aspects of this. Sentences can be entered as texts via the editor (in one of several possible formats), by using a sentence window (or directly from MS Excel with DDE): | ||||||||
|
||||||||
|
Using data (facts/sentences) from the web The web is usually the best place to look for facts, whether these are weather statistics, stock prices or economic indicators. Pro/3 has a utility to translate HTML-formatted files to a format which can be entered into the KB (delimited text format is normally the best choice). |
||||||||
|
Step 3 - Defining Sentence Rules |
||||||||
|
||||||||
|
Step 3b - Enhancing the Sentence Model |
||||||||
|
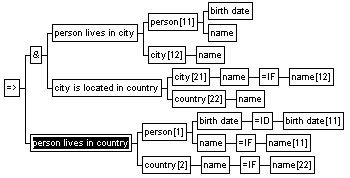
No additional sentence modeling is required to enter the person lives in country rule, since both the predicate type and the entity type in the conclusion are known (i.e. they are already used in the sentences in the condition of the rule). This is often not the case, and consequently, new sentence model entities are added as required when rules are defined. |
||||||||
|
||||||||
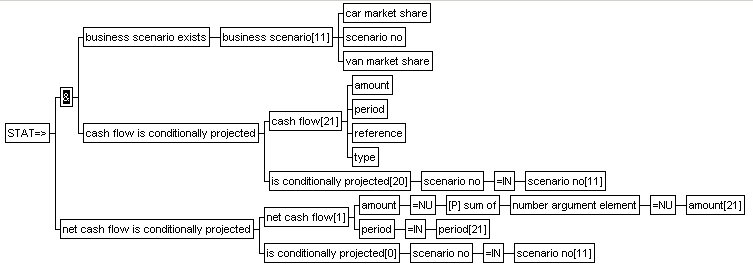
| The CASHFLOW|3-rule derives net cash flows from cash flows, the CASHFLOW|1-rule derives net discounted cash flows from the net cash flows, and finally, the CASHFLOW|2-rule derives net present values from the net discounted cash flows: | ||||||||
|
|
||||||||
|
|
||||||||
|
|
||||||||
|
Step 3c - Defining Functions |
||||||||
| Functions can be used to model sentence derivations which cannot be explicitly represented in sentence rules. Functions should generally be regarded as a last resort approach, since they, like traditional computer programs, are more prone to bugs and interpretation problems than derivation logic directly represented in sentence rules. Note that Pro/3 comes with a set of built-in functions which can be used with less caution. | ||||||||
|
Step 4 (optional) - Defining Certainty Rules |
||||||||
|
The problem-area model concepts presented so far have dealt with "crisp logic", somewhat simplistically: logic where expressions are either true or false. It can be beneficial in some problem-areas also to use degrees of true or false, i.e. to have a measure for expressions such as "quite true", "absolutely false", "uncertain" etc. Pro/3 uses certainty factors for modeling degrees of certainty. Certainty factors are computed by networks of certainty rules. A certainty rule is "called" from a sentence rule (and/or from other certainty rules), and through various processing features, returns a certainty factor. Certainty rules include
Certainty rules are typically used to draw inferences from the KB i.e. by "querying" sentences derived from sentence rules, or by questioning the KE interactively during the processing of a query (or sentence derivation). |