|
The natural language interface, and the distinction between this external format (NL-format) and the internal format (IF-format) inside the knowledge base (KB), is an important feature of Pro/3. Pro/3 incorporates a variety of user interfaces i.e.
interfaces between the knowledge engineer (KE) and the KB. The
most important and ultimate interface is based on knowledge
represented as natural language sentences. The terminological
knowledge defines the natural language sentence constituents (syntagms and synonyms) used in a Pro/3 model. Refer to natural
language interface.
All syntagms and synonyms for a given natural language is
referred to as a terminology. The KB can contain more than one
terminology, however one of the terminologies is always
designated as the current terminology (or current language). You
can change the current terminology during a session with Pro/3.
|
|||||||||
|
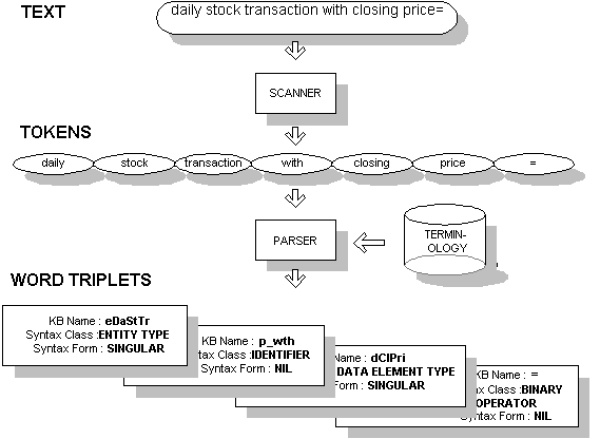
A natural language sentence is viewed by Pro/3 as a sequence of syntagms. A syntagm is sequence of one or more "words" (more precisely "tokens"), which represents one lexical concept.
Comma is also a syntagm in Pro/3. The exclamation sign (!) is particularly important, since it signifies the end of a Pro/3 sentence (i.e. a sentence is not terminated by a period as is usually the case in English and other languages). All syntagms used in a Pro/3 KB must be defined as such. A syntagm definition associates the natural language word sequence (NL name) with an internal one-word KB name (an internal name/identifier used within the KB), and a syntactical classification (syntax class and syntax form). The KB name, the syntax class and the syntax form is referred to as a word triplet. Note that the syntagm and the word triplet combined, sometimes are referred to as a "syntagm" in Pro/3. A set of syntagms are called a terminology. |
|||||||||
|
Translation of NL-format knowledge into internal format knowledge consists of four main steps:
|
|||||||||
|
The translation process involves various sources of ambiguities. There are a few potential token-level ambiguites. These are resolved by syntactic conventions described in the NL syntax. Token-to-syntagm mapping ambiguities are not resolved - it is considered as a non-deterministic process. Consequently, the mapping results in possible several alternative syntagm sequences (referred as different interpretations in Pro/3). In almost all cases only one interpretation is parsable into a sentence. Pro/3 will always use the first parsable interpretation.
|
|||||||||
|
Pro/3 permits that two or more syntagms can be associated with the same word triplet. One of the syntagms are designated as the main syntagm (that is, it is used when word triplet is translated back to syntagms). The alternative syntagms are referred to as synonyms.
|
|||||||||
|
A terminology is a complete set of syntagms (and synonyms) for a given language (e.g. English). Complete means that it includes syntagms for all entity types, predicate types, data element types, function declarations, certainty rules, the identifiers used in the model as well as all Pro/3's meta sentence model, built-in functions and standard identifiers. The latter groups of syntagms are pre-defined in a set of standard source files:
A Pro/3 model can include more than one terminology (e.g. both an English and a Danish terminology). You can input parts of the model in one terminology and parts of the model in another terminology. You can switch between terminologies during a session with Pro/3. One terminology is designated as the current terminology at any point of time. Input and output always take place in the current terminology. The standard Pro/3 terminology is: |
|||||||||
|
**************************************************************************************************** Pro/3 v.3.12.01: Terminology KB : [A] c:\pro3kbs\mc\mc.3kb TERMINOLOGY : English SEGMENT CONTEXT: Pro/3 **************************************************************************************************** # *& 's ( ) * + , - ... / : ; < <= <> = =* =*CF =*DEC =*IF =*IN =*INC =*KB =*LI =*NU =*PR =*SY =*XD =*XDR =*XDT =*XT =CF =DEC =DR =ID =IF =IN =INC =IT =KB =LI =NU =PR =SY =XD =XDT =XT > >= ACTUAL_PARAMETERS AND_CALLS AND_RULE ANNOTATION ANY *APR ASCENDING ORDER *AUG Apr *April Aug *August BAYESIAN_RULE BAY_CALLS CALL_SWITCH_RULE CERTAINTY RULE CERTAINTY FACTOR CONTEXT_CALLS DATA ELEMENT TYPE DATABASE DATA_RULE DATETIME *DB - identifier DB *DB - configurations *DB - configuration DB-configuration DB-configurations DB-identifier DBs *DEC DECISION ISSUE DECREMENT FACTOR DEFAULT VALUE DERIVED SENTENCE TYPE DESCENDING ORDER DETERMINISTIC FUNCTION CALL DETERMINISTIC DATA ELEMENT REFERENCE DISCRETE_MAP DO NOT KNOW DURATION Dec *December ENTITY TYPE ESSENTIAL EVALUATED EXECUTION TRACE EXISTENCE CONDITION EXTRAPOLATE AT START AND END EXTRAPOLATE AT END ONLY EXTRAPOLATE AT START ONLY English *FEB FORMAL_PARAMETERS FUNCTION DEFINITION FUNCTION DECLARATION FUNCTION Feb *February *I - TIME *I - DATE IDENTIFIER IMMATERIAL IMPORTANT INCREMENT FACTOR INPUTTED SENTENCE TYPE INTEGER INTERNAL TIME INTERNAL INTERNAL DATE *JAN *JUL *JUN Jan *January Jul *July Jun *June *KB - name KB timing events KB timing event *KB - queries *KB - query KB-name KB-queries KB-query LIST OF DURATION LIST OF DATETIME *LIST OF X - TIMES *LIST OF X - DATES LIST OF XML TIMES LIST OF XML DATES LIST OF DECREMENT FACTORS LIST OF INCREMENT FACTORS LIST OF PROBABILITY FACTORS LIST OF CERTAINTY FACTORS LIST OF ANY VALUES *LIST OF I - TIMES LIST OF INTERNAL TIMES LIST OF NUMBERS LIST OF STRINGS LIST OF INTEGERS LIST OF INTERNALS LIST OF SYMBOLS LIST OF IDENTIFIERS *LIST OF I - DATES LIST OF INTERNAL DATES MAP_FROMS MAP_RULE MAP_TOS *MAR *MAY Mar *March May *NATURAL LANGUAGE NIL NL *NL - name NL-name NO EXTRAPOLATION NO *NON - DETERMINISTIC FUNCTION CALL *NON - DETERMINISTIC DATA ELEMENT REFERENCE NONDETERMINISTIC FUNCTION CALL NONDETERMINISTIC DATA ELEMENT REFERENCE NOT_RULE *NOV NUMBER NUMERICAL_MAP Norwegian Nov *November *OCT OF LIMITED IMPORTANCE OR_CALLS OR_RULE OUT OF CONTEXT Oct *October PARAMETER_SWITCH_RULE PLURAL / UNDETERMINED PLURAL / DETERMINED PLURAL PR PREDICATE TYPE PREFIKS / UNDETERMINED PREFIX / DETERMINED PROBABILITY FACTOR PROCEDURE *PROLOG *Pro / 3 versions *Pro / 3 version Pro/3 versions Pro/3 version QUERY QUERY_RULE QUESTION QUESTION_RULE *RAM - chains *RAM - chain RAM chains RAM chain REALM SEGMENT SENTENCE TYPE SENTENCE RULE *SEP SINGULAR / UNDETERMINED SINGULAR / DETERMINED SINGULAR STRING SWITCH_CALLS SWITCH_RULE SYMBOL Sep *September VERY IMPORTANT *X - TIME *X - DATE XML TIME XML DATE YES [ ] ^ a absolute number absolute integer *access - mode access mode accumulation of accumulation rule actual parameters *all about all alternatives *an and annotation annotations *apr are in the model are in the KB are in the terminology are recorded are in the sentence model are noted are public chains are in external DB argument argument element *aug average of average binary operator called rule type called actual parameters *called certainty - rule called certainty rule cardinality certainty tree evaluation certainty tree evaluation certainty rule evaluations certainty rule evaluation *certainty - rule reasoning tree certainty rule reasoning tree *certainty - rule name certainty rule name *certainty - factor certainty factor certainty factor mirror chain *chain - name chain name chains concatenation *configuration - value *configuration - parameter configuration value configuration parameter correlation of correlation rule count data element types data element type data element data element list date interpolation date addition date series date date interpolation rule date series element *date series - step *date series - end *date series - start date series step date series end date series start datestring datetime series *day - number day number day number in week day component *dec decision issue importance default default value define defines dependency status derive derives determine determines deterministic functions deterministic function difference div *divided by dividend division divisor domain domain name domains duration increment dynamic element no end value of end point end value *end - number end number end end datetime end time end date endpoint of entity types entity type entity type name *equals error *evaluation - type evaluation type event reference extrapolation faculty *false *feb first date first first number argument element fixed for format generalization rule given *greater or equal to *greater than *identifier - trace identifier trace if sets of if implication rule *increment - number increment number increment index in integer list index update integer integer division integer series *integer - trace integer trace integer null value integer divisor integer dividend internal date of yyyymmdd internal date number internal date of dmy *internals - trace internals trace interogative interpolation interpolation rule *is unlike *is like *is greater or equal to *is less or equal to *is unequal to *is less than *is greater than is in the model is in the KB is in the terminology is recorded is in the sentence model is it true that is defined by is noted is a public chain is in external DB issue increment factor issue decrement factor *it can be concluded that it is true that *it is not false that it is not true that *jan *jul *jun knowledge base path knowledge base file language leap year length *less or equal to *less than like list of strings list of numbers list of durations list of datetimes *list of x - times *list of x - dates list of xml times list of xml dates list of integers list element no list loading lower case mapped from *mar max token length *max realm - name length *max KB - name length max point max value max KB-name length max realm-name length maximum of maximum point of maximum number maximum duration maximum datetime maximum xml time maximum xml date maximum integer maximum selection rule *may mean of mean menu name *menu - ID menu-ID message midpoint min point min value minimum of minimum point of minimum number minimum duration minimum datetime minimum xml time minimum xml date minimum integer minimum selection rule mod *modulo *month - number month number month month no month name month component no of months no of days no of days between no of years node *node - type *node - class *node - name node type node class node name nodes *non - deterministic functions *non - deterministic function nondeterministic functions nondeterministic function none not note *nov now null value number number series *number of sentences where *number of sentences of *number of *number - trace number trace number argument element *oct of *on the premises that sets of *on the premise that sets of *on the premises that *on the premise that or order other operator *output - width output width *output - format output format owner menu parameter list parameter no parameters place position predecessor predicate types predicate type predicate type name procedure procedures quarter query text query parameters query parameter query menus query menu ranking rule *read - only *read - write readonly readwrite *return - domain return domain return value *root certainty - rule root certainty rule *rule - value rule value *rule with certainty - rule call rule with certainty-rule call second date second number argument element segment name select sentence count sentence type *sep series element *series - step *series - end *series - start series step series end series start sort sort element no standard ranking standard deviation of standard deviation start value of start point start value *start - number start number start start datetime start time start date startpoint of static statistical rule statistical ranking status string *string - trace string trace substring successor sum of sum *symbol - trace symbol trace synonym synonyms syntagm syntagms syntax form syntax class terminologies terminology the then *this * this time series time timeseries of timeseries title today token list trace *true unary / binary operator *unequal unique of unique selection rule unlike upper case value of value version weekday number what is known about what where which who *whom with *x - date xml date xml date of internal date xml date of YYYYMMDD year year component { } *~ s *** END OF REPORT *** |