|
SIMPLE RULES |
|
SIMPLE IMPLICATION RULES
|
|
GENERALIZATION RULES
AND RULES WITH LOGICAL OR
|
|
|
SET RULES |
|
STATISTICAL RULES
|
|
RULES CALLING INEXACT RULES
|
|
SELECTION, INTERPOLATION,
RANKING, CORRELATION AND
ACCUMULATION RULES
|
|
|
|
Rules
can not be directly or indirectly recursive. This is related
to the processing of the rules by the sentence
derivation process.
|
|
Generalization Rules - Rules with
logical OR (v)
|
|
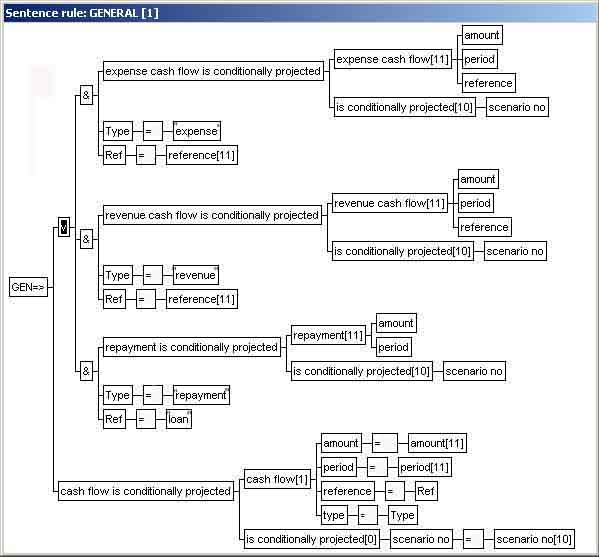
In the Rent-a-Car KB there are several
types of cash flows: expense cash flows, revenue cash flows,
repayments etc. For the purpose of deriving aggregations such as
net cash flows, discounted cash flows and ultimately net present
values, it is practical to derive generic cash flows from the
various cash flow types. The following rule does just that:
|
|
|
|
The generalization rule is mainly
a rule editor input-concept, since all rules containing logical OR-operators (v)
are stored in the KB as a OR-free sub-rules (the OR-operators are
eliminated during translation to internal format). Consequently, rules with OR are
not supported in PR-format. The above rule is represented as three sub-rules in the KB,
corresponding to the three branches of the OR-operator. The
following sub-rule represents the first branch of the
OR-operator:
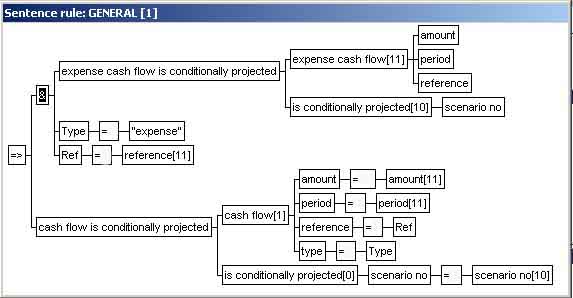
Type="expense" (i.e.
the assignment of the literal "expense" to the variable named Type, is
an example of a variable condition component of a rule).
|
|
Rules with open entity type arguments
|
|
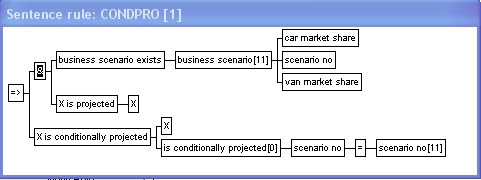
The entity type arguments in the rules
above are fixed, that is, explicitly specified. Entity type
arguments can also be open or unspecified, i.e. represented by a
variable in the rule-tree:
|
|
|
|
The rule above states that everything
which is projected also
is conditionally projected for all
existing business scenarios. is projected is a
unary predicate type (one entity type
argument). Binary predicate types can have one or both entity
types unspecified (open).
Note that
rules with open entity arguments only can be interpreted via the sentence
derivation process. The rules can not be handled by the
inference engine directly.
|
|
Function calls in sentence rules
|
|
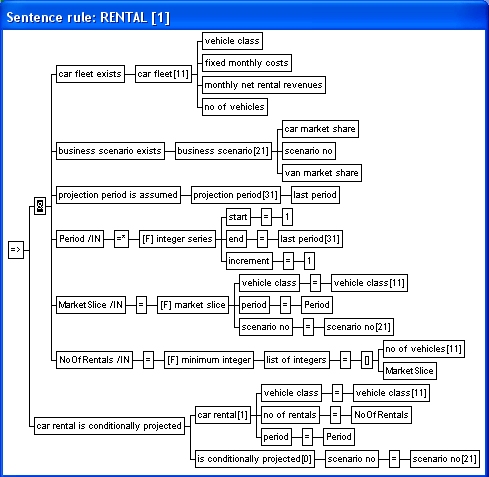
Let's look at a more complex rule:
|
|
|
|
The rule above has six AND'ed condition
components: three unary sentence conditions and three variable
conditions. The first variable condition involves a call to a
non-deterministic function (the built-in function integer series), while the remaining two involve calls to
deterministic functions. The last call to the built-in function minimum
integer involves an integer list domain parameter called
list of integers. The actual parameter in in the rule is a list
with two integers: the data element no of vehicles (from the first sentence condition) and the rule
variable
MarketSlice.
Note that variables are suffixed with domain indicators (e.g. /IN
for an integer domain variable).
Note the
following restrictions in calling functions:
- functions can
only be called in the rule's condition;
- function calls
can only be "assigned" to a simple variable (directly or via
an expression);
- a
function-call can not be used as actual parameter in
another function call.
|
|
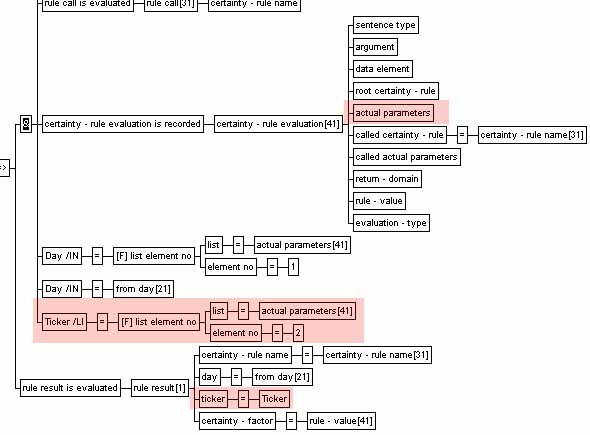
REFERRING
INDIVIDUAL ELEMENTS IN LISTS
Individual list
elements (values) can only be accessed indirectly by using the built-in
function list element no:
|
|
|
|
actual parameters is a list-domain data element type (of the
ANY-domain, which means that the elements of the list can be of different
domains). The second actual parameter is accessed via a function call and
indirectly assigned to the ticker data element type in the
conclusion. (The certainty-rule evaluation is recorded is a
system-generated sentence, which captures the result of an evaluation of a
inexact rule).
|
|
Rules Working On Sets Of
Sentences
|
|
Set rules
conclude sentences which are derived in various ways from sets of
other sentences (or sentence combinations ANDed together). Set rules use
(call) at least one of Pro/3's procedures in the rule's conclusion.
This call looks superficially like a function call, but has otherwise no
similarity with such calls. The inference engine's processing of a set rule can
be more easily understood in relational database terms:
- The
condition part of the rule defines a condition set,
a (usually) non-normalized table where each row either is a sentence or two or
more sentences joined together.
- The condition set is
sometimes viewed as two or more condition sub-sets. Sub-sets are
defined as rows in the table with the same value for one or more of the data
element types (columns).
- The procedures refer to various type of
operations on the data element types of the condition (sub-)set.
These operations include sums, averages, minimums. maximums and
several other. There are two sub-types of set rules:
statistical rules and selection, interpolation, ranking,
correlation and
accumulation rules.
The following discusses
the set rules in somewhat summarized manner. A
comprehensive set of examples with explanation of the different rules in
more detail, is mandatory to fully understand the concept and workings of the
set rules.
Note the following
restrictions in using procedures:
- procedures can only
be used in the rule's conclusion;
- procedures are
normally assigned directly to a data element type, however some procedures
can form part of an expression (assigned to a data element type);
- a procedure can not
be used as actual parameter to another procedure.
|
|
Statistical
Rules |
|
The statistical rules assign values to the data elements in the concluded
sentence
by using one or
more of the statistical procedures. The value assigned to one or more of
the data elements in the conclusion, is determined through a call to one of the statistical
procedures. There are 13 statistical procedures in addition to the
TIMESERIES_OF-procedure
(described under).
The statistical
procedures take one, two or no parameters. No parameters are needed by the
SENTENCE_COUNT procedure
since it simply returns the number of sentences in the condition
(sub-)set. All other procedures require the
argument-parameter
i.e. the data element from the condition sentence set which is computed on. The
procedures which require two parameters view the sentences in condition
set as an ordered set. The second parameter (series)
is the data element which defines the order (sequence) of the sentences in the
condition set.
There is no limit the
number or combination of procedure calls in the conclusion. However, the
series-parameter must
always be the same data element. The inference will check this integrity constraint upon
execution of the rule.
|
| NAME
(NL) |
NAME
(KB) |
FUNCTIONALITY
- PARAMETERS |
COMPONENT# IN TIMESERIES
TERM-STRING DATA ELEMENT TYPE |
|
SUM_OF |
p3_rSum |
Computes the sum of the argument data
element in the condition (sub-)set. |
1 |
|
SENTENCE_COUNT |
p3_rCnt |
Determines the number of sentences in the
condition (sub-)set. |
2 |
|
START_VALUE_OF |
p3_rStv |
Determines
the start value of the argument
data element in the
condition (sub-)set according to the sequence determined by the series
data element. |
3 |
|
AVERAGE_OF |
p3_rAvg |
Computes
the average of the argument data element in the condition
(sub-)set. |
4 |
|
MEAN_OF |
p3_rMea |
Computes the
mean of the argument data element in the condition (sub-)set. |
5 |
|
END_VALUE_OF |
p3_rEtv |
Determines
the end value of the argument
data element in the
condition (sub-)set according to the sequence determined by the series
data element. |
6 |
|
STANDARD_DEVIATION_OF |
p3_rStd |
Computes the
standard deviation of the argument data element in the
condition (sub-)set. |
7 |
|
MINIMUM_OF |
p3_rMin |
Determines
the minimum of the argument data element in the condition
(sub-)set. |
8 |
|
MAXIMUM_OF |
p3_rMax |
Determines
the maximum of the argument data element in the condition
(sub-)set. |
9 |
|
STARTPOINT_OF |
p3_rStim |
Determines
the minimum value of the series data element in the condition
(sub-)set (= the start of the sequence). |
11 |
|
ENDPOINT_OF |
p3_rEtim |
Determines
the maximum value of the series data element in the condition
(sub-)set (= the start of the sequence). |
12 |
|
MINIMUM_POINT_OF |
p3_rMit |
Determines
the value of the series data element where the argument data element
has its minimum value in the condition (sub-)set. |
13 |
|
MAXIMUM_POINT_OF |
p3_rMat |
Determines
the value of the series data element where the argument data element
has its maximum value in the condition (sub-)set. |
14 |
|
TIMESERIES_OF |
p3_rTS |
Returns a
term-string domain data element with 14 components, corresponding to
the 13 procedures above and a 14th element representing the difference
between MAXIMUM_OF and MINIMUM_OF. The sequence of the components is the
same as shown in this table with the difference-component between
MAXIMUM_OF and STARTPOINT_OF. The procedure has two parameters:
argument: the data element subject to time series analysis;
series: the series sequencing data element |
|
|
|
Selection, interpolation,
ranking, correlation and accumulation rules
|
|
The model for Pro/3's interpretation (processing) of a selection/interpolation/accumulation
rule is as follows:
- The
condition part of the rule, in a relational database analogy, defines a condition set,
a (usually) non-normalized table joined together of known sentences
(tables). The condition sentence set is generated as defined by the rule's
condition part. The procedure calls do not have any significance in
generating the condition set. (The condition set (depending on the actual rule), may or may not
be viewed as two or more condition sub-sets. Sub-sets are
defined as condition sentences with same value for on or more of the data
elements. ).
- An adjusted condition set is generated
from the set in (1), and manipulated according to the the procedure calls. This set is a subset of the
condition set when the MAXIMUM_OF, MINIMUM_OF or
UNIQUE_OF procedures are used. It can be either
a subset or a superset when the
INTERPOLATION
or
DATE_INTERPOLATION procedures
are used. The adjusted condition set has the same number of
sentences when the ACCUMULATION_OF,
STANDARD_RANKING or
CORRELATION_OF procedures are used.
- The concluded sentences are generated from the adjusted condition set.
A rule must include one, and only one,
of the following five procedure call types (corresponding to the five main
procedure types):
- one or more calls to the
ACCUMULATION_OF
procedure - whereby given data element(s) are accumulated over a series of
sentences;
- one call to the
MAXIMUM_OF procedure - whereby a
sentence with the highest value of a given data element in set of sentences
is selected. The
MAXIMUM_OF procedure can
optionally be used in combination with any number of calls to the
SELECT
sub-procedure;
- one call to the
MINIMUM_OF procedure - whereby a
sentence with the lowest value of a given data element in set of sentences
is selected. The
MINIMUM_OF procedure can
optionally be used in combination with any number of calls to the
SELECT
sub-procedure;
- one or more call to the
UNIQUE_OF
procedure - whereby sentences with unique values for given data elements are
selected from a set of sentences. The
UNIQUE_OF procedure can
optionally be used in combination with any number of calls to the
SELECT
sub-procedure;
- one call to the
INTERPOLATION or
DATE_INTERPOLATION procedure -
whereby gaps in an ordered set of sentences are filled through
interpolation. the
INTERPOLATION procedure can
optionally be used in combination with any number of calls to the
MIDPOINT,
PREDECESSOR, SUCCESSOR and
FIXED sub-procedures.
- one call to the
STANDARD_RANKING or
STATISTICAL_RANKING procedure and one or more calls to the
SORT
procedure, whereby the sentences are assigned a rank depending on the
sequence of sentences after sorting.
- one call to the
CORRELATION_OF
procedure.
Note that the
series-parameter must
always be the same data element in rules where more than one procedure uses
this parameter.
The selection, interpolation and
accumulation procedures can best be understood by considering examples.
|
| NAME
(NL) |
NAME
(KB) |
FUNCTIONALITY
- PARAMETERS |
|
ACCUMULATION_OF |
p3_rAcc |
Accumulates
the number
argument element
(data element) in the condition (sub-)set over the series
defined by the series data element (the series is always traversed
in ascending
order of the series data element). |
|
MAXIMUM_OF |
p3_rMax |
Determines
the maximum value of the argument element
(data element) in the condition (sub-)set. Maximum value refers
to the sorting-wise highest value (which applies to integers, numbers and
strings).
Can be used in combination with sub-procedure
SELECT.
|
|
MINIMUM_OF |
p3_rMin |
Determines
the minimum value of the argument element
( data element) in the condition (sub-)set. Minimum value refers
to the sorting-wise highest value (which applies to integers, numbers and
strings).
Can be used in combination with sub-procedure
SELECT.
|
|
UNIQUE_OF |
p3_rUn |
Determines
sentences in the condition (sub-)set which has unique values of the number
argument element
(data element). If more than one calls to the Unique procedure are made, then
uniqueness is defined as the situation where at least one of the data
elements are unequal.
Can
be used in combination with sub-procedure SELECT.
|
|
INTERPOLATION |
p3_rCip |
Interpolates
(and optionally extrapolates) sentences in the condition (sub-)set, i.e.
where there are missing sentences as defined by the series element (data element), which defines the ordering of the
condition (sub-)sets. Other parameters are:
extrapolation:
whether or not extrapolation is carried out on the start and/or end of the
series (value is either of the Pro/3 identifiers EXTRAPOLATE_AT_START_ONLY,
EXTRAPOLATE_AT_END_ONLY, EXTRAPOLATE_AT_START_AND_END or NO_EXTRAPOLATION);
series-start:
the start value for the sequence (not used in case of EXTRAPOLATE_AT_END_ONLY or NO_EXTRAPOLATION);
series-end:
the end value for the sequence (not used in case if EXTRAPOLATE_AT_START_ONLY or NO_EXTRAPOLATION); series-step:
the sequence increment value.
Note! series-start and series-end
can be a constant or a data element from the condition set (it cannot
be a simple variable or an expression). extrapolation
is always an identifier constant.
Can be
used in combination with sub-procedures FIXED, MIDPOINT, SUCCESSOR and
PREDECESSOR.
|
|
DATE_INTERPOLATION |
p3_rCipxd |
Interpolates
(and optionally extrapolates) sentences in the condition (sub-)set, i.e.
where there are missing sentences as defined by the date series element
(data element), which defines the ordering of the
condition (sub-)sets. Other parameters are:
extrapolation:
whether or not extrapolation is carried out on the start and/or end of the
series (value is either of the Pro/3 identifiers EXTRAPOLATE_AT_START_ONLY,
EXTRAPOLATE_AT_END_ONLY, EXTRAPOLATE_AT_START_AND_END or NO_EXTRAPOLATION);
date series-start:
the start value for the sequence (not used in case of EXTRAPOLATE AT END
ONLY or NO EXTRAPOLATION);
date series-end:
the end value for the sequence (not used in case if EXTRAPOLATE_AT_START_ONLY or NO_EXTRAPOLATION); date series-step:
the sequence increment value.
Note! date series-start and
date series-end can be a constant or a data element from the condition set (it cannot
be a simple variable or an expression). extrapolation
is always an identifier constant.
Can be
used in combination with sub-procedures FIXED, MIDPOINT, SUCCESSOR and
PREDECESSOR.
|
|
STANDARD_RANKING |
p3_rRank |
Determines the ranking of sentences in the
condition (sub-)sets i.e. on the basis of one or more calls to the sort
sub-procedure. The order parameter
determines the type of ranking i.e. actual values must be the Pro/3 identifiers ASCENDING (sentence
with lowest value gets rank 1) or DESCENDING (sentence with highest
value gets rank 1).
Ties are ranked with same integer
e.g. 1,2,2,4,6,...
Must
be used in combination with one or more calls to the SORT
sub-procedure. Can be used in combination with SELECT
sub-procedure.
|
|
STATISTICAL_RANKING |
p3_rRnks |
Determines the ranking of sentences in the
condition (sub-)sets i.e. on the basis of one or more calls to the sort
sub-procedure. The order parameter
determines the type of ranking i.e.
actual values must be the Pro/3 identifiers ASCENDING (sentence
with lowest value gets rank 1.0) or DESCENDING (sentence with highest
value gets rank 1.0).
Ties are ranked with by average
values e.g. 1.0,2.5,2.5,4.0,6.0,...
Must
be used in combination with one or more calls to the SORT
sub-procedure. Can be used in combination with SELECT
sub-procedure.
|
|
CORRELATION_OF |
p3_rCorr |
Determines
the coefficient of correlation between the first number argument
element (data element) and the second number argument element
(data elements) in the condition (sub-)set. The coefficient is set to
1 in sets with cardinality 1 (where correlation is meaningless).
|
| |
|
|
|
FIXED |
p3_rDf |
argument
element:
the data element who will
be interpolated by using a fixed value; default
value: the fixed value to be used (Note! only constant
values allowed). |
|
MIDPOINT |
p3_rMnVa |
Specifies
the "midpoint" interpolation method for the number
argument element. |
|
SUCCESSOR |
p3_rUpp |
Specifies
the "successor" interpolation method for the number
argument element. |
|
PREDECESSOR |
p3_rLow |
Specifies
the "predecessor" interpolation method for the number
argument element. |
|
SELECT |
p3_rAssg |
Specifies
that the argument element is to be used as value for this data
element. |
|
SORT |
p3_rSort |
Determines
the the sort sequence on which rankings are based (ref. standard ranking
and statistical ranking procedures). The sort
element no is an integer in the range [1,N], where N is the number of sorting elements (sort calls) in the rule. The sort element
with no 1 is the most significant sort key. |
|
|
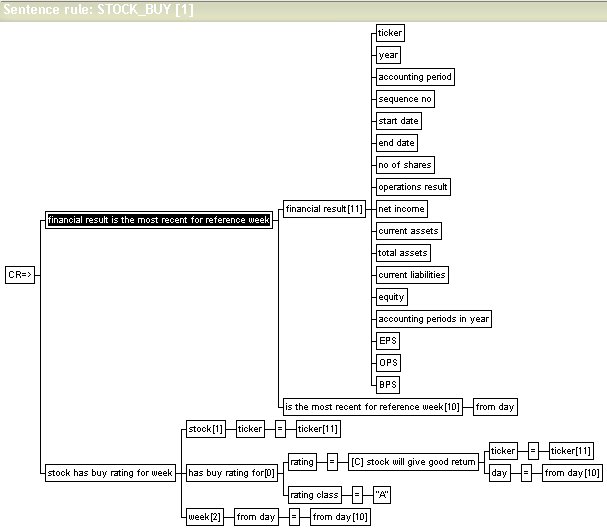
Rules calling inexact rules
|
|
Inexact
rules are used (called) in exactly the same way
as functions in sentence rules, with the difference that
inexact rule calls require a different internal
processing of the rule. The rule is processed as if was a statistical rule. The certainty factor returned by the
called rule is either assigned directly to a data element in the
conclusion, or indirectly in an expression.
|
|
|
|
Note that Pro/3 is unconcerned with the
semantic interpretation of the returned certainty factor. This is
just another data element value. The certainty factor may state
the certainty of the sentence as a whole (this might be the
typical way of using certainty data elements), but this is not
necessarily so. The correct interpretation is only known by the KE.
Note the following
restrictions in calling inexact rules:
- inexact rule calls
can only be called in the rule's conclusion, i.e. rule calls are "assigned" to a simple data element type (directly
or via an expression);
- an inexact rule
call can not be used as actual parameter in another inexact
rule call.
|