|
A rule specifies that certain sentences
can be derived from other sentences, for example, how the net present value of a project can be derived from the
project's discounted cash flows. A second rule might specify how
the discounted cash flows can be derived from the project's cash
flows (and a discount rate assumption), a third set of rules how
cash flows are generalizations of various types of payments and
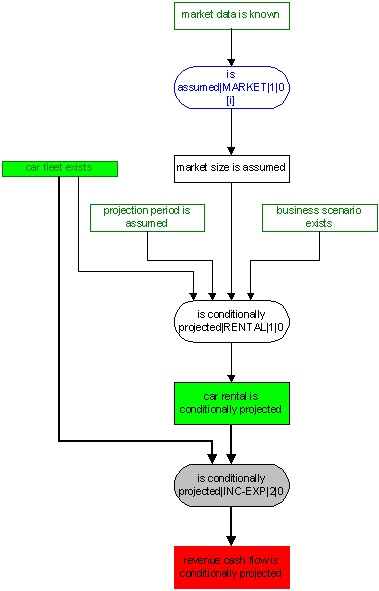
receipts etc. The Summit-model illustrates some aspects of forward and backward chaining. FORWARD CHAINING SUPER-STRUCTURE Rather than interpreting all rules on the fly, the normal approach in Pro/3 is to use the forward chaining super-structure whereby all possible sentences are derived once and for all and stored in the KB. Repeated re-derivations will only take place when needed, that is when rules or sentences which affect (are determinants for) a derived sentence have been changed. How does Pro/3 whether or not rules should be interpreted on the fly? One of the fields in a database record is the record type field (see DB internals). The value of this field is an integer which actually incorporates three sub-codes. One of the sub-fields is record status, which is reflected in the sign of the integer, such that a negative value signifies an inactive record, while a positive value signifies an active record. This sub-code applies to sentence rule records only. Inactive rules are ignored by the inference engine, with the effect that responses to queries are based only active rules. Consequently, a KB where all queries are to be processed on the fly, have all sentence rule records active, while a KB using the foward chaining super-structure normally has all rule records as inactive. It is assumed then, with respect to inactive rules, that all sentences which can be derived from these rules already are stored in the KB. It is also possible to combine the two approaches by setting the sentence rule record to the appropriate status (see Sentence Rule-window). The forward chaining super-structure implies some administrative overheads on Pro/3's part, which needs to keep track of all dependencies between sentences and rules, as well as the status of derivations. To carry out this task, Pro/3 maintains a knowledge dependency graph. This graph is directed and acyclic (which imposes some fundamental limitations on the structure of sentence rules discussed under). The direction of the graph signifies the sequence of derivation (the direction is from condition to conclusion - from determinant to dependent). Derived sentences stored in the KB are known as such by Pro/3 through the record type field (i.e. derived sentences have type 1, while sentences explicitly entered by the KE have type 2). |
||||||||||||||||||||||||
|
||||||||||||||||||||||||
|
||||||||||||||||||||||||
|
||||||||||||||||||||||||
|
Keeping the graph up-to-date Pro/3 maintains the derivation status field by tracking all changes to sentence type populations, sentence rules, inexact rules and functions (elements in these sets are referred to as knowledge nodes Note that this tracking ignores changes to derived sentences, as these principally should be only changed (automatically) through the sentence derivation process. However, it is fully possible to perform such changes. On the other hand, the dependency graph is updated if entire population of derived sentences (all derived sentences of the same type) are deleted. Subscribed sentence type represent a potential problem in this context, since changes in the external SQL tables where they are stored, take place outside Pro/3, i.e. without causing a change in the derivation status in the dependency graph. In the present version of Pro/3, the Sentence Derivation-window has an option to refresh all subscriptions. This will trigger the necessary updates to a graph i.e. in situations where a sentence type has changed. The refresh must be done prior to sentence derivation. Internal representation of the graph The graph is represented as a set of sentences in the KB: the dependency node with node type N and node name AA determines the dependency node with node type M and node name BB with derivation status S!The table under shows eight dependency sentences. Note that node types as well as the dependency status are represented by integers. The dependency graph (and the sentence model graph) are loaded into a Pro/3 RAM data structure upon opening of the KB. Changes in the graphs during processing, are only reflected in this data structure while interacting with Pro/3 (i.e. they are not reflected in the KB). The graphs are stored in the KB upon closing. Queries only consider knowledge in the KB. This means that queries involving the graphs (such as the standard Pro/3 knowledge dependency queries), will not reflect changes which have taken place after the KB was opened. To compensate for this potential problem, a command to update the graph knowledge in the KB has been included the KB-menu. This command can then be used prior to running such queries. 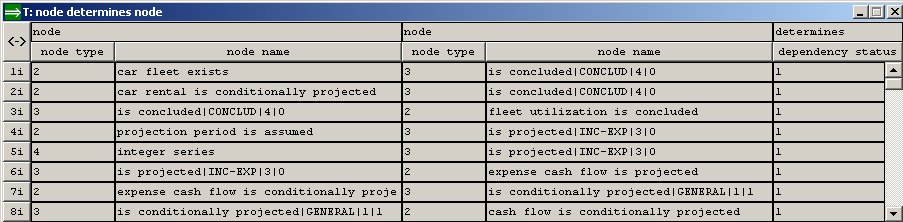
Drawing the graph The dependency graph can be drawn as a tree directly or exported to a graph drawing package. Pro/3 permits directly as well as indirectly recursive functions (a function calling itself). However, such cycles can not be represented in the acyclic dependency graph and are ignored (this does not impair the sentence derivation logic). Consider the following example: |
||||||||||||||||||||||||
|
||||||||||||||||||||||||
|
This way of treating recursive functions do not have any side-effects within Pro/3. Sentence Derivation Process Steps Sentence derivation is a four-step process invoked by the KE through the Sentence Derivation-window, which also includes options for (re-)derivation of all sentences in the KB (regardless of derivation status), re-generation of the dependency graph and refresh of subscribed sentence types. There is also a derivation strategy report which shows the required sequence of sentence type derivations (and the sentence rules involved). The four steps are as follows: Step 0: (optional) REFRESHING SUBSCRIBED SENTENCE TYPES See subscribed sentence types. Step 1: CREATING THE DERIVATION GRAPH Before the derivation of sentences starts, Pro/3 needs to know: (i) the sentence types which require (re-)derivation, and (ii) the appropriate sequence of sentence type derivations (sentences are derived type by type). This information is found in the dependency graph, however a slightly different graph, the derivation graph, is generated as the first step in the derivation (the predicate used in the derivation graph is derives (rather than determines). The derivation graph is generated from the dependency graph and has a similar structure, however, with only two node types: |
||||||||||||||||||||||||
Inexact rules and functions Inexact rules and functions are not needed in the derivation graph. Dependencies from a sentence type or sentence rule node via inexact rules or functions to another sentence type or sentence rule are added. The dependencies ST->IR and IR->SR, will be represented as one edge in the derivation graph i.e. ST->SR. Rules with open entity type arguments - derived rules The other important difference between the two graphs, is that sentence group-nodes are
used in the dependency graph, but not used in the derivation graph (these nodes
originate from sentence
rules with open entity arguments). |
||||||||||||||||||||||||
|
||||||||||||||||||||||||
|
Step 2: CASCADING 'UN-DERIVED' STATUSES Pro/3 keeps track of each dependency's derivation status as records are added, deleted or modified in the KB. However, the status is not cascaded recursively through the graph. The cascading is done in the derivation graph just after its creation, such that the successors of all dependencies with status 0 also are set to 0. |
||||||||||||||||||||||||
|
Step 3: DERIVING SENTENCE TYPES Sentence types are derived one by one in determinant-dependent order - a sentence type can be derived after all it's determinant sentence types have been derived. Sentence types without determinants are not derived (they correspond to sentence types defined by explicitly entered sentences only). Only sentence rules can be direct determinants of a sentence type in the derivation graph, and vice versa only sentence types can be direct determinants of sentence rules. The derivation of one sentence type involves four steps:
|
||||||||||||||||||||||||
|
||||||||||||||||||||||||
|
Step
4: SETTING
DEPENDENCY GRAPH STATUS The fourth and last step is to set all dependencies as 'derived' in the dependency graph. |
||||||||||||||||||||||||
|
SENTENCE DERIVATION STATISTICS Pro/3 logs a few facts of the most recent derivation of each sentence type (sentence derivation statistics is in the KB-sentences). This includes the number of sentences derived, the derivation time (in seconds) and derivation start- and end-time. The information is displayed in the Sentence Derivation-window and used in the Sentence-report. The information to estimate the time it will take to re-derive all sentence types. |
||||||||||||||||||||||||
|
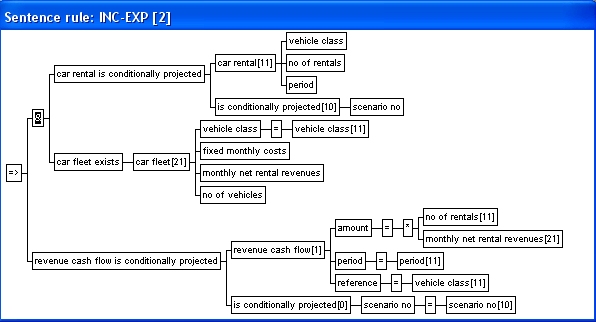
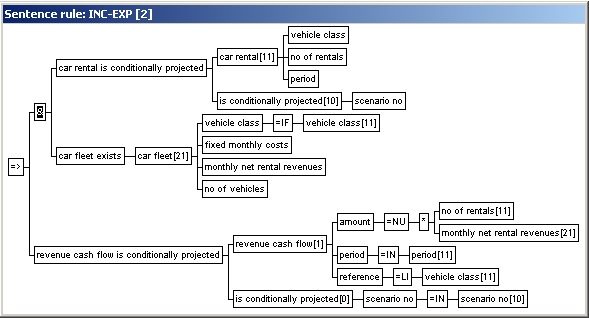
The dependency graph (and derivation graph) cannot include cycles. This imposes some essential limitations on rules. The same sentence type can not appear both in the condition and in the conclusion (directly and indirectly i.e. via other sentence rules) This means that you cannot type rules of the type:
(Rule 1 is never acceptable, while Rule 2 and 3 are unacceptable in the same database - they could exist in the same knowledge base in a recursive multi-KB configuration). There are different ways of working around this constraint, as illustrated by the following example. |
||||||||||||||||||||||||
|
Example
The rule
if
the cash flow with amount N and currency DEM exists, then the
cash flows with amount (N/1.85) and currency US$ exists,
is not allowed since the
cash flow exists sentence type appear both in the condition and
in the conclusion. The rule can be re-structured in different
ways:
|
||||||||||||||||||||||||
|
Another approach would be to use a multi-KB configuration, since cycles involving two or more of the participating KBs are possible. See cyclic multi-KBs for details. |
||||||||||||||||||||||||