|
|||||||||
|
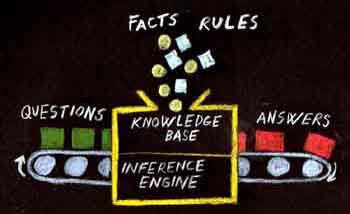
First of all - where do facts and
rules come from? Facts and rules come from a knowledge engineer (KE for
short), who either is an expert in the area of interest, or one who has access to
such an expert. The KE formulates the knowledge so that Pro/3
can make use of it in a way that makes the system produce something
useful. This means that he or she also needs to know Pro/3 - its knowledge
representation concepts, its inference methods and the practical
facilities included in the system.
You cannot understand Pro/3 sentence rules unless you understand the concept of Pro/3 facts (sentences). |
|||||||||
|
Facts in Pro/3 are called sentences,
and a sentence rule describes how sentences are
derived from other sentences.
There are several types of sentence rules:
|
|||||||||
|
Example 1 |
|||||||||
|
|||||||||
|
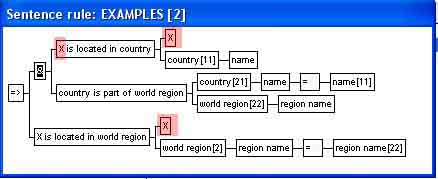
Can Pro/3 answer the question which
manufacturers are located in the world region with region name Europe?
on the basis of the above sentences? No! because Pro/3 has no inherent
geographical knowledge, and cannot connect the two sentence types without
first being told the underlying and very subtle rule that "if a
manufacturer is located in a certain country and that country is part of a
certain world region, then the manufacturer is located in that world
region".
Sentence rules are visualized as trees (rule trees), and usually "drawn" as such with Pro/3's rule editor. The rule tree for this example could look like: |
|||||||||
|
|
|||||||||
|
The condition consists of two parts
joined with logical and (& in the tree), each corresponding to
a sentence type (manufacturer is located in country and country
is part of world region). The conclusion is the sentence type manufacturer
is located in world region.
The interpretation of the rule can easiest be explained with SQL-terminology. manufacturer is located in country and country is part of world region would then be understood as tables:
Notice the numbering of entity types and predicate types in the rule (shown inside [ ]-brackets). The numbering is done automatically by the rule editor, and the purpose is simply to establish a unique qualifier for the data element types. The numbers have otherwise no particular significance, however the following conventions are used by the rule editor:
Note also the assignment/equality-operator =. The operator either compares the value of the operands on its left and right side (that is, if the left side operand already has a value), or it assigns the value of the right-side operand to the left side operand. The right side is either a data element type within a sentence-structure (as in this example) or it is simple variable unrelated to any of the sentence structures. Pro/3 is now able to answer the question - the sentence rule has described how sentences of type manufacturer is located in world region from the two sentence types manufacturer is located in country and country is part of world region. |
|||||||||
|
|||||||||
| Note that the condition sentences can be sentences entered into the knowledge base as facts, or they can be sentences concluded from other sentences rules (in any levels of recursion). | |||||||||
|
OPEN ENTITY TYPE ARGUMENTS Example 2 |
|||||||||
| The rule over could have been written in a more general way: "if X is located in a certain country and that country is part of a certain world region, then X is located in that world region". The manufacturer entity type has been replaced by an argument variable X. The rule will now apply to any entity type which are located in a country (e.g. banks, shops and so on). | |||||||||
|
|
|||||||||
| As in PROLOG, variable names start with an upper case letter (or an underscore). However, a word starting with an upper case letter is not necessarily a variable since names (identifiers) also can start with upper case letters (Peter is clearly permitted as a name in Pro/3). This will not cause ambiguity since all names are stored in the knowledge base (in the terminology) and thus known to Pro/3. | |||||||||
|
Functions could be considered a third class of rules (in addition to
sentence rules and inexact rules). Like inexact rules, functions
return one value although this values does not need to be simple (it could
for example be a list of values). Unlike inexact rules, functions
can fail i.e. fail to return a value. Functions usually have
one or more (input) parameters, but can also be defined without
parameters.
Functions are interpreted by the same PROLOG-type inference engine as sentence rules. Pro/3 comes with a set of standard functions (source) which can be loaded into to the knowledge base. There are also few functions built into the inference engine. Functions are called by sentence rules by assigning it (with an assignment operator) to a simple variable in the rule's condition as in the following example: |
|||||||||
|
Example 3 |
|||||||||
|
|
|||||||||
|
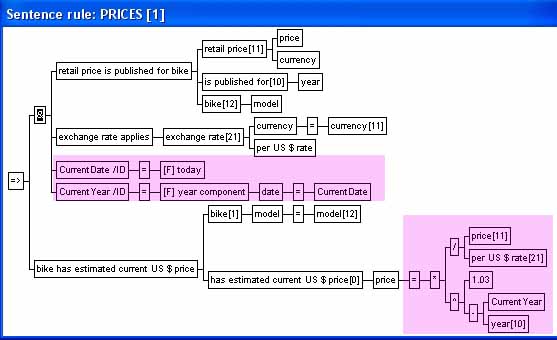
The Prices[1]-rule has four
conditions. The upper two conditions are sentence conditions, while
the lower two are variable conditions. A variable condition
consists of a simple variable (the left side), an assignment or comparison
operator and a right side expression. The third condition,
consequently has the Current Date as its left side simple variable =
as its assignment operator. The
/ID is
the variable's domain indicator, i.e. the identifier-domain
(refer to sentence
model domains for all domain short forms).
The right side is a call to the built-in function today which returns the current date (and has no input parameters). The fourth and last condition is another variable condition which assigns the year component of the current date to Current Year by calling the Pro/3 function year component. This function has one input parameter date (with Current Date as actual parameter i.e. the value assigned to the formal parameter when the function is called). Note that rules are interpreted from top to bottom (this corresponds to left-to-right interpretation of its internal representation). Expressions can be simple (e.g. a literal value or simple variable) or arbitrarily complex (expressions are structured as trees). The expression assigned to the price data element type in corresponds to:
|
|||||||||
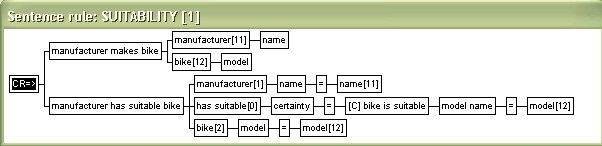
| On the surface of it, inexact rule calls look exactly like function calls (note that the rule editor prefixes functions names with [F] and IR rule names with [C] for clarity). However, the inference engine handles functions and inexact rules entirely different, and rule calls are only possible in sentence rules especially classified as "calling inexact rules type of rules" (the root of the rule tree shows the rule's classification, e.g. => for simple implication rules and CR=> for rules calling IR rules). IR rule calls (= the value returned by the rule), can only be assigned a data element type in the rule's conclusion. | |||||||||
| Example 4 | |||||||||
|
|
|||||||||
|
Set rules conclude sentences which are derived in various ways from sets of other sentences (or sentence combinations ANDed together). Set rules use (call) at least one of Pro/3's procedures in the rule's conclusion. This call looks superficially like a function call, but has otherwise no similarity with such calls. The inference engine's processing of a set rule can be more easily understood in relational database terms:
|
|||||||||
|
STATISTICAL RULES
Example 5 |
|||||||||
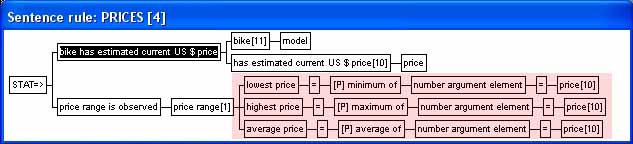
| The MC knowledge base knows the estimated current US$ price for the bikes in knowledge base via the rule in Example 3.It could be useful to know the lowest, highest and average price for these bikes e.g. expressed as a sentence price range is observed. A set rule, more precisely a statistical rule, can be used for this purpose: | |||||||||
|
|
|||||||||
|
The condition set in this example is all the bike
has estimated current US$ price sentences. Note the three procedure
calls in the conclusion. Most procedures have parameters - all three rules
use a generic data element type number argument element as
parameter. Procedure-names are prefixed with [P]
by the rule editor (for clarity).
Only one sentence is derived from this rule: |
|||||||||
|
|||||||||
|
Example 6 |
|||||||||
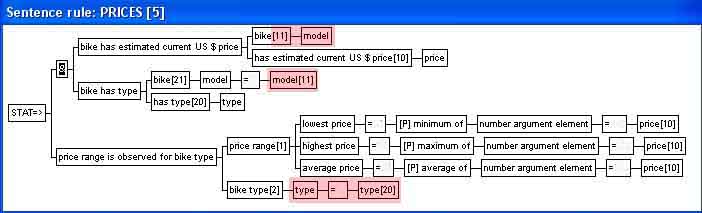
| The bikes have a type-classification: | |||||||||
|
|||||||||
| It could also be useful to know the price range per classification-type. This could be expressed as price range is observed for bike type, and the rule could look like: | |||||||||
|
|
|||||||||
| The condition set is now a join between two sentence types bike has estimated current US$ price and bike has type. The assignment of the type data element type from the condition set to one of the data element types in the conclusion (which also is called type), signifies that one sentence of price range figures is to be generated from each set of condition sentences which has the same value for type: | |||||||||
|
- which price ranges are observed for which bike types? price range with lowest price 17317, highest price 44421 and average price 27587 is observed for bike type with type superbike! price range with lowest price 8293, highest price 15024 and average price 12144 is observed for bike type with type roadster! price range with lowest price 12388, highest price 12388 and average price 12388 is observed for bike type with type tourer! price range with lowest price 6829, highest price 14624 and average price 10086 is observed for bike type with type cruiser! price range with lowest price 7561, highest price 33172 and average price 15876 is observed for bike type with type sportsbike! price range with lowest price 12059, highest price 16722 and average price 14565 is observed for bike type with type sports tourer! price range with lowest price 5288, highest price 14781 and average price 9614 is observed for bike type with type trailie! price range with lowest price 3276, highest price 20193 and average price 10470 is observed for bike type with type all - round! |
|||||||||
| There are all in all 13 procedures which can be used in statistical rules: sum, mean, average, standard deviation, minimum, maximum, start value, end value, start point, end point, minimum point and maximum point, and finally timeseries which returns a term-string domain value data element with all of the preceding values. | |||||||||
|
SELECTION, INTERPOLATION, RANKING, CORRELATION AND ACCUMULATION RULES |
|||||||||
| The second group of set rules includes eight different rule types: numeric interpolation, date interpolation, value accumulation, ranking, correlation, selection of unique, selection of maximum and selection of minimum. These rules are less intuitive to use than the statistical rules, and needs to be studied carefully. | |||||||||
|
Example 7 |
|||||||||
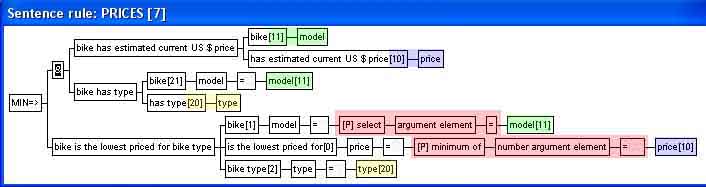
| The rule in Example 6 was used to derive the price range for each type of bike. A minimum-selection rule can be used to derive the lowest price bike for each type. | |||||||||
|
|
|||||||||
| Note the important difference between the assignments to the model data element type and the type data element in the conclusion. The assignment in the first case uses the select-procedure, while the latter uses a direct assignment. The direct assignment to type signifies that a sentence will be concluded for each distinct type in the condition set. The select-procedure, on the other hand, signifies that the model to be assigned to the sentences in the conclusion is the model of the bike with the minimum price: | |||||||||
|
|||||||||
|
Example 8 |
|||||||||
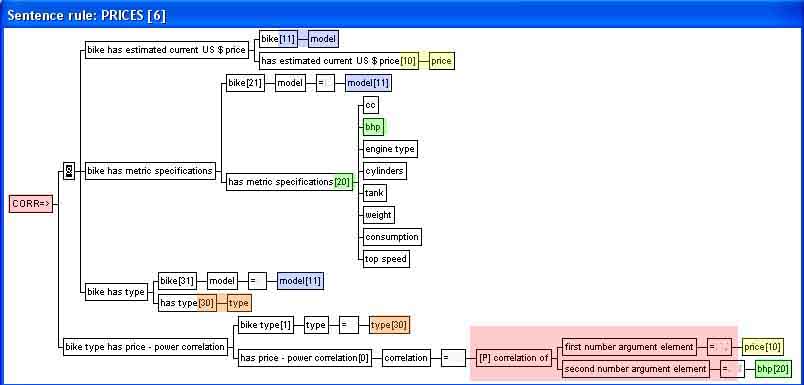
| The goal of last sentence rule example is to determine the correlation between price and engine power for each of the bike types: | |||||||||
|
|
|||||||||
| The correlation-procedure has two parameters - the two data element types in the condition set to be correlated. | |||||||||
|