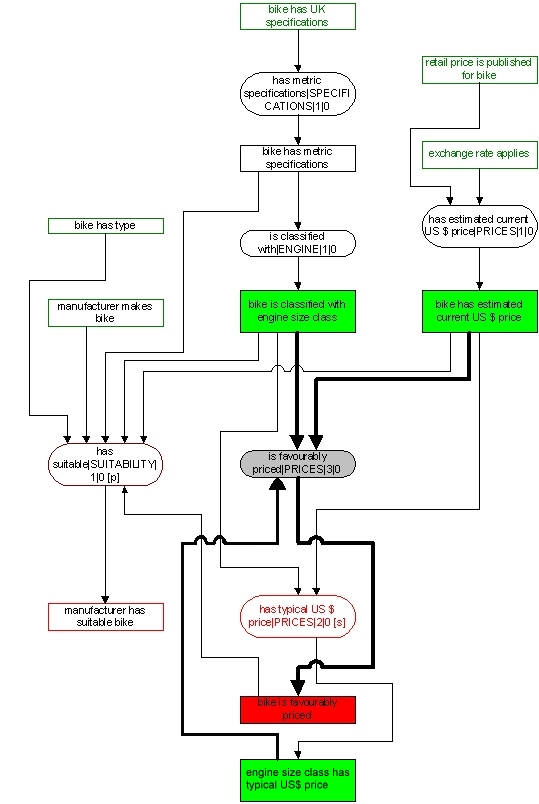
| A sentence rule concludes a set of sentences of particular type, typically on the basis of (on the conditions of) other sentences. Consider the part of the MC-model which conclude bike is favourably priced sentences. This sentence type (red rectangle) is concluded by a single rule PRICES|30 (gray oval), which has three sentence types as conditions i.e. engine size class has typical US$ price, bike is classified and bike has estimated current US$ price (green rectangles): |
|
|
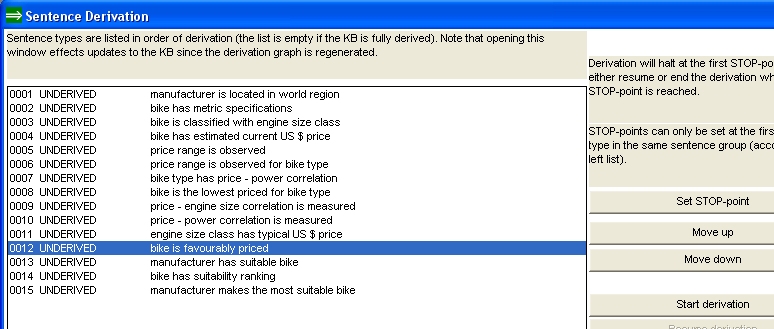
| The sentence derivation process derives sentences (sentence types) in a forward chaining way such that before concluding (deriving) bike is favourable priced sentences, the process derives engine size class has typical US$ price, bike is classified and bike has estimated current US$ price sentences (recursively), until it encounters the entry points in the graph (drawn with a green pen) which always are sentences in the knowledge base (that is, sentences directly entered/loaded into to the KB as opposed to sentences concluded by rules). This sequencing logic is visualized in the Sentence Derivation-window: |
|
|
|
The sentence derivation process
stores all derived sentences in the KB, which means that validations can
be carried out step by step by step, by validating a concluded sentence
type by analyzing its conditional sentence types. This complexity of this
validation obviously increase by the the number of rules and conditional
sentence types involved, and by the size of the sentence populations.
Sentence rules calling certainty rules entails the same validations as sketched here, in addition to a separate evaluation of the called certainty rule (network). Functions should as much as possible be validated separately before being used in sentence rules. The basic method for validating functions is to store in the KB and then run a number of function queries to check if the return values are correct. |